Git Squash: Keep Clean of Your Git Commit History
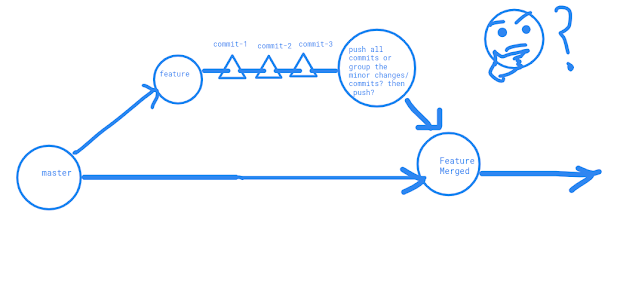
I magine, you are assigned to write a new feature of the main product. How do you start? You copy the source code, start coding for feature, write, test, write, fix bugs selfly explored, optimize code, fix typos or such minor task,s and time to time you have to commit your changes so that you don’t lose the valuable work you have done for the feature. So, we can guess, you may have commits of test code, some type fixing commit, commit of missing comments etc. At last, you have completed your feature! Wow! Gre a t work! But wait! You want to have a look at your commit history and applied: git log - -oneline Facepalm situation! You got all your commits including minor changes, typos, bug fixing, code-comment all types of commits in separate commits! How the hell shall I clean my messy commit history? Feels awkward, right? No worries buddy! Git has given us the power to present them nicely, combined them into a single commit. This way, you can group your commits so that you don’t h...


